Motivation
In our recent projects and with the development of the vantage6 UI, we encountered several issues that required us to rethink the current vantage6 task flow.
Improving User Experience
In this blogpost the latest user interface and algorithm store were introduced. Creating this user interface gave rise to new challenges.
- When the available data column names needed to be displayed, they first needed to be retrieved from the nodes. This is a challenge as the infrastructure is agnostic to the type of data source. This means that algorithms are required to perform this task.
- When data preprocessing steps are applied to the data, the user also needs to be informed of the available data items.
Expensive Queries & Sharing of Queries
Using the OHDSI tools in vantage6 we experienced that queries can take a long time to complete.
- When used in combination algorithms that take N iterations to complete you would have to execute this query also N times.
- Queries can be complex to build so being able to share the it with other algorithms would save development time.
- Not all users should be able to query the data directly. For example, in the IDEA4RC there is the need to query the data source once after the query has been approved in another governance application. After the approval, the user in that case is able to compute as much as he or she would like.
Community Algorithms
Sharing algorithm is greatly appreciated in the vantage6 community, and also allows a researcher to have a bigger impact with their work. To accomodate the desire to share algorithms with other members of the community, we launched the community store. There are two reasons why sharing is not as easy as it should be:
- Every project is using custom methods to retrieve data from the source (e.g. one project uses a CSV file and another uses SQL). Since the compute and data retrieval is done in the same call, you would need to clone the project and write your own data retrieval process. This results in multiple copies of an algorithm, which makes it difficult to maintain - if an algorithm change is required, how do you ensure it is updated for all projects using that algorithm if they use copies?
- In case an algorithm is written in a specific language, the data retrieval process should also be written in the same language.
Requirements
In order to solve the challenges described we need to:
- Split data extraction, preprocessing and compute steps in algorithms. This way components can be re-used and metadata of intermediate data frames can be shared with the user (e.g. column names)
- Support popular programming languages (R, Python, Java, etc.)
- Allow the intermediate data frames to be shared with other users in an entire organization or collaboration
- Have multiple data frames per session to support multi-database algorithms
- Allow modification of an existing data frame
- Rebuild the data frames in case the source data has changed
Implementation
To support these use cases we introduced two new vantage6 concepts: Dataframe and Session. Sessions are a collection of dataframes that can be made available to yourself, to your organization or to the entire collaboration. Each session can contain several dataframes. Each dataframe consists of columns, types and values.
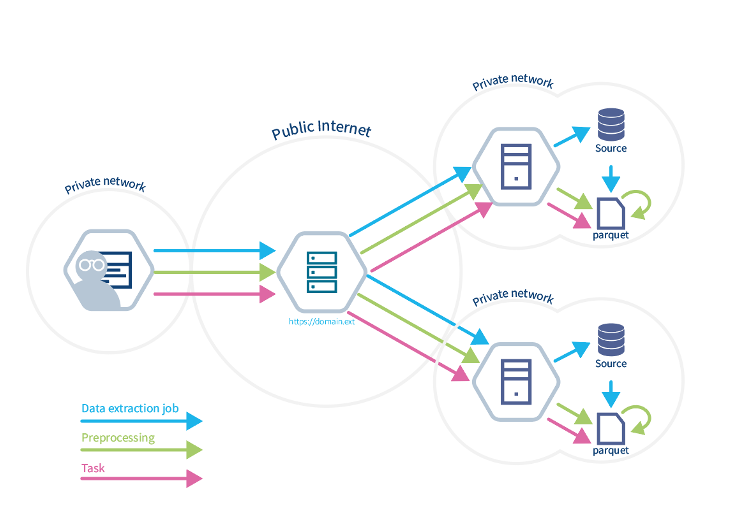
When a new dataframe is created in a session nodes will first execute the data-extraction step, to obtain a tabular dataset from the data source. In case of a CSV, this could be as simple as a copy and in the case of a SQL database this step should also contain a query. The interface of the data extraction step is fully controlled by the algorithm developer.
Once the data is extracted, it is stored in a parquet file. This format is supported in all important languages. Other languages than Python can therefore also easily comply to the session requirements.
After a data extraction step, the user can send a preprocessing step or a compute step. A preprocessing step will modify the dataframe in some way (e.g. modifying its type from `int` to `string` or computing the age from a date-of-birth).
Both the UI and python client have been modified to support this new workflow. The creation of a task will remain the same, except that you now specify which session and data frame to use for the computation.