Different Ways of Partitioning Data
In Federated Learning, there are two common ways in which data can be partitioned across parties:
In horizontally-partitioned data, distinct parties have the same features for different patients. A typical example of this partition is an international collaboration where we want to perform a comparison across the populations of two countries.
In vertically-partitioned data, distinct parties have the same patients but with different features. For instance, we could be interested in combining data spread across different organizations from the same group of patients.
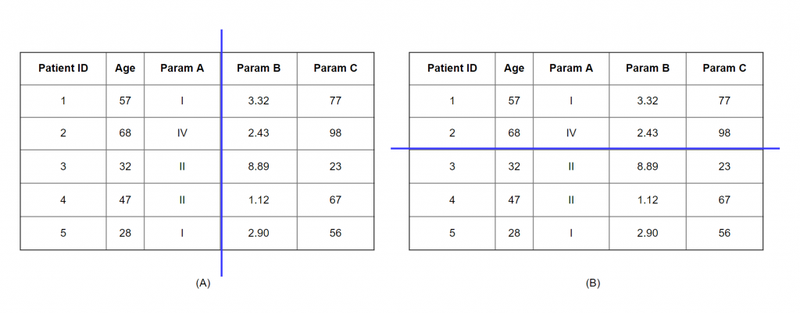
(A) A vertical partitioned dataset contains the same patients but different features.
(B) A horizontal partitioned dataset contains the same features for different patients.
vantage6 has been used successfully in several FL applications that use horizontally-partitioned data. However, developing and implementing algorithms for the vertical use case is more complex and therefore have different requirements.
This is also why Multi-Party Computation (MPC) algorithms are an interesting alternative for analyzing vertically-partitioned data. However, MPC comes with its own set of challenges. In this post, we would like to talk a little bit more about this.
Problem 1 - Overhead of Repeatedly Starting Docker Containers
In the trolltunga version of vantage6, the overhead time (i.e., communication + startup) of a single task consumes several seconds. Most of this time is spent starting the Docker container
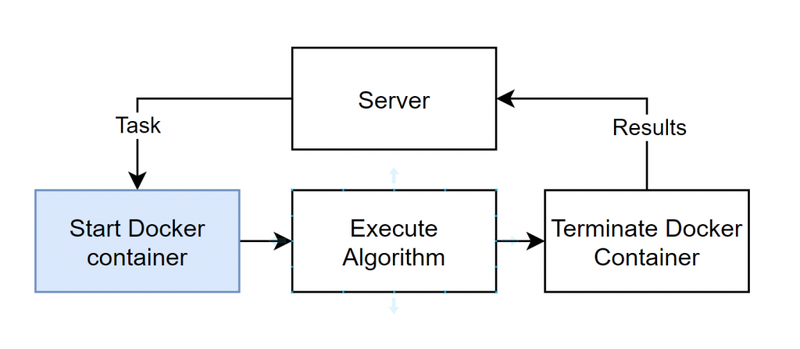
Flow of a single task at a single node.
MPC algorithms require heavy communication between the parties. Therefore, this process of starting and stopping Docker containers is repeated many times. This would make the time needed for an MPC algorithm depend mostly on the time required to start a Docker container.
Problem 2 - Missing (semi-)Direct Communication Between Algorithm Containers
In vantage6 trolltunga, there is no way to directly communicate with an algorithm container (which is located in a different machine). The only way to get information from one station to another is to first do the computation at data station 1, collect the results, and send these to data station 2. For most horizontal cases this is sufficient.
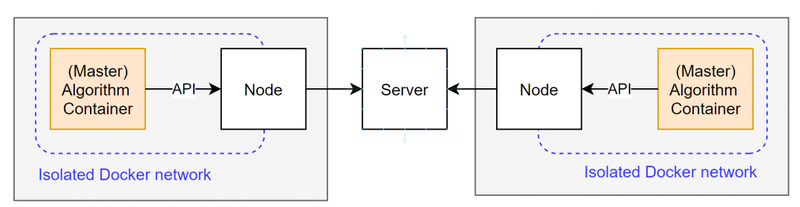
Direct communication between nodes is not possible. All communication goes through the server API.
However, when using third-party MPC libraries (like MPyC or Scale mamba), it is common to directly communicate with other parties in the network using a bidirectional socket connection. Therefore, integrating these third-party libraries into vantage6 trolltunga involves completely re-writing the communication protocol inside these libraries.
Why not using a public IP?
Direct communication between two (or more) data stations would be possible if the nodes had a public IP. This is not the case and desired as this would make a node more vulnerable and more difficult to setup.
Towards vantage6 – 3.0.0
In order to facilitate MPC solutions in the future, we propose the following features for a future release of vantage6 – 3.0.0.
1) Service Algorithm Containers
Algorithm containers are no longer terminating after completing a single task. The algorithm service container terminates either by a trigger or after a given period of time. Methods can be triggered, by users or other containers, and results can be send and collected at any time.
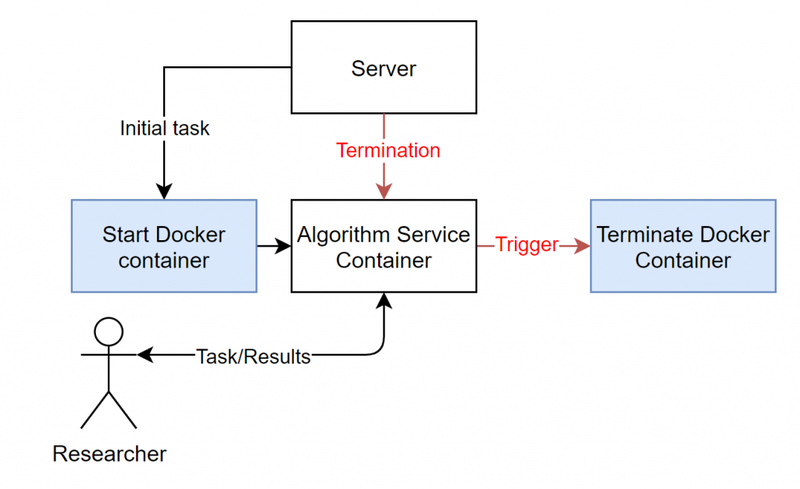
The researcher can be replaced by another algorithm (service) container.
2) Direct Socket Communication Between (Service) Containers
Direct socket communication solves two problems at once. Firstly, it allows algorithm developers to use third-party MPC dependencies. Secondly, it gives allows to communicate with service algorithm containers.
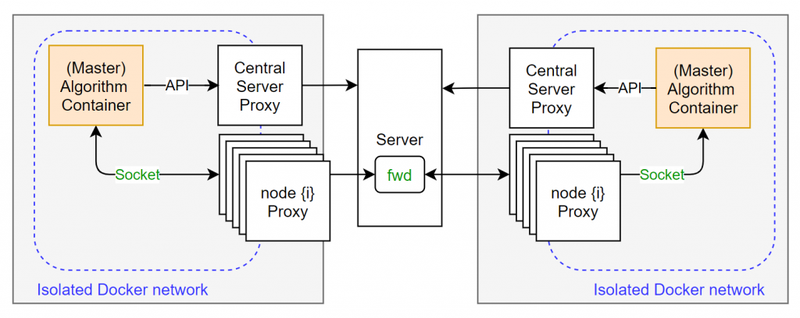
Each node creates a proxy for all the other organization that are in the collaboration
Every node is part of a single collaboration. In other words for every collaboration an organization takes part in, they should have a running node. Therefore the node should create a separate proxy for all of the other organizations in the collaboration. This way every other party has a unique address which can be used by the algorithm containers.